経緯

もとの声の特徴が強く出ていて、かつ歌の特徴も捉えた細やかな調整に感動した
必要なもの
歌のmidiファイル
変換元データについて
自分が歌わせたい曲の歌声のみの音源があればそれを使えますが、なかなかありません。なので何かしらの方法を使って歌声音源を持ってこないといけません例えば
- 曲とカラオケ音源を使って歌声を抜き出す方法
- midiファイルをからNeutrinoを使って歌声を生成する方法
があります。先に上のをやろうとしましたが、できなかったので下の方法を解説します。
準備
Reaper
音MAD作者御用達のアプリ

gitのインストール(ubuntu使ってる人はいらないはず)

実行してNext連打で大丈夫です。
python3.10のインストール
ほかにpythonを使う人、別件でほかのバージョンのpythonが入っている場合はpyenvで検索(ここでは解説しません)
Windows
python3.10を指定されているので最新のものではなく3.10.xをダウンロードしましょう。
Windows embeddable packageは実行ファイルが入っているだけなので、設定が簡単なインストーラバージョンをダウンロードしましょう。
実行してすぐ add python.exe to PATH にチェックを入れてください。
忘れていたら一度アンインストールしてやり直してください
非公式ですがわかりやすいのでこちらからでもOKです。

実行してすぐ add python.exe to PATH にチェックを入れて続行しましょう。
忘れていたら一度アンインストールしてやり直してください
Ubuntu
sudo apt update
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install python3.10
この後のコードでpythonをpython3.10に置き換えて実行してください
cudaのインストール

自分のOSとバージョンをダウンロードしましょう
ローカルとネットワークバージョンを迷ったらネットワークバージョンで大丈夫です。
実行してエクスプレスインストールしてください。
cuddn

会員登録が必要です。登録しましょう
基本ダウンロードするのは数字の一番大きいものです
ダウンロードしたら展開して中身をC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\[バージョン名]に入れましょう。
そしてシステム変数「CUDNN_PATH」値 「C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\[バージョン名]」を追加してください
CUDA_PATHと同じ値になるはずなのでコピペすると楽
システム変数追加のやり方

Visual Studio
C++のデスクトップ用開発にチェックをいれてください

ここまで来たら再起動しましょう(多分自動で再起動する)
本体とその他ダウンロード
再起動したらwinキー+Rキーを押しcmdと入力してください
git clone https://github.com/svc-develop-team/so-vits-svc/これでso-vits-svcをダウンロードできました
cd so-vits-svc 途中でタブキーを押すと自動で入力してくれます。
そのあと
pip install editdistance
pip install SoundFile
pip install sounddevice
pip install requests==2.28.1
pip install onnx onnxsim onnxoptimizer
pip install scipy==1.9.3
pip install Flask==2.1.2 Flask_Cors==3.0.10
pip install playsound==1.3.0 PyAudio==0.2.12
pip install pydub==0.25.1
pip install pyworld
pip install tqdm==4.63.0
pip install scikit-maad
pip install praat-parselmouth
pip install gradio==3.9
pip install starlette==0.20.4
pip install tensorboard
pip install librosa
pip install fairseq==0.12.2インストールすべきモジュールはhttps://economylife.net/so-vits-svc-windows/を参考にしました。
ありがとうございます。
しかしfairseqがインストールできなかったのでeditdistanceもインストールしています。
checkpoint_best_legacy_500.ptをダウンロードしso-vits-svc\hubertにいれ
G_0.pthとD_0.pthをダウンロードしso-vits-svc\logs\44kに入れます
ヴォーカル合成用
ヴォーカルデータがある人はダウンロードしなくていいです。
NEUTRINO
windowsバージョンと歌声ライブラリから何人か
(本体に一人入っていますが、後でさらに変換するときの保険のため複数人を推奨)
ubuntuの人はonlineバージョンと歌声ライブラリをダウンロードしましょう

本体、歌声ライブラリ、どちらも展開し、
歌声ライブラリのファイル名が、大文字ローマ字のフォルダを本体のmodelファイルに入れます。
ubuntuの人はリンク先を読んでください

Musescore
バージョンが3から4になって再生ボタンが押せないバグを見なくなりました。
実行してmusescoreを押すとインストールが始まります。

linux版もありますが日本語入力ができないのでWindowsでやりましょう。
NEUTRINOで歌唱データを作成
学習データの用意
NEUTRINOで歌声データを作ります。
まずネットからmidiファイルを拾ってきます。曲名+midiで出てくると思います。
ダウンロードしたらreaperで開きます。
- ○個のmidiトラックをreaper内の新規トラックとして展開
- midiテンポをプロジェクトテンポに挿入
この二つにチェックを入れてOKを押しましょう。
このままだと音が出ないので、下のどれかのFXボタンを押し追加ボタンを押します。
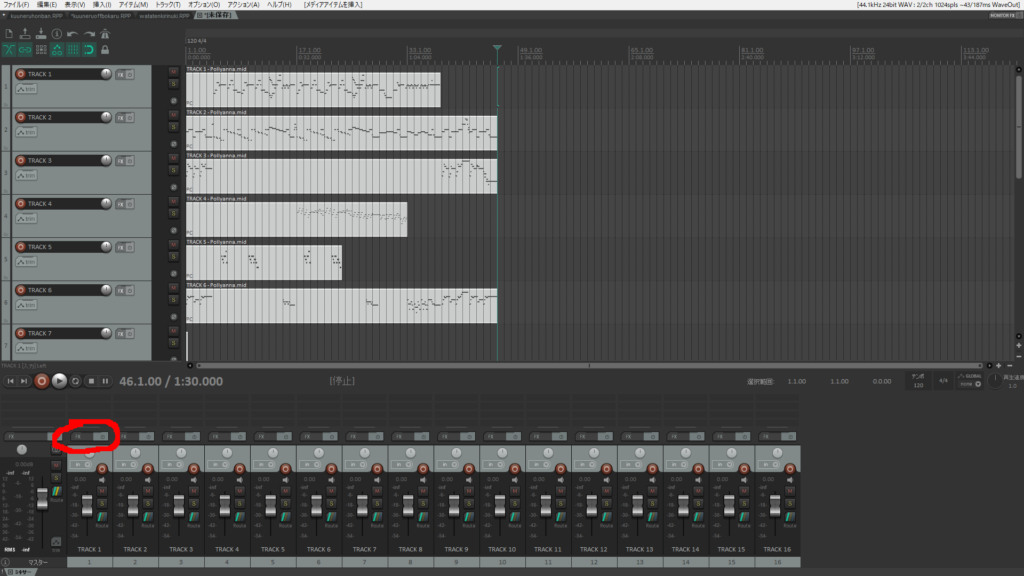
VSTiのVSTi:ReaSynth (Cockos)を選択し追加します。
この繰り返しで使用したいボーカルを特定してください
特定したらそのパートを選択しコピー、そして左上のファイルから新しいタブを開きそこに貼り付けてください
そしてファイルからMIDIファイルを出力をしましょう。場所はわかればどこでもいいです。
(デフォルトはC:\Users\ユーザー名\OneDrive\ドキュメント\REAPER Mediaだったと思います)
Musescoreで歌詞を入力する
さっき出力したmidiファイルを開きます。そうすると楽譜が出ると思います。一つ目の符号を選択し
追加>テキスト>歌詞を選択します。そしてひらがな1文字で歌詞を入力します。矢印キーで次の符号へ行きます。再生ボタンを押すとメロディーが流れるので、音を聞いて調整しましょう
基本すべての符号に歌詞をつけてください。符号が余るときは符号を変えたりタイを使って下さい
終わったらエクスポートしますMusicXMLで非圧縮形式であることを確認してください。
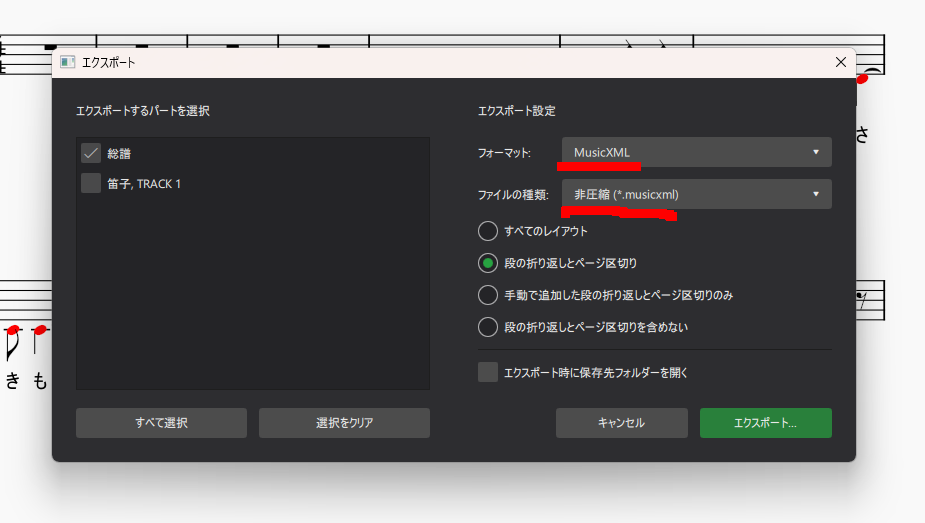
出力先は先ほどダウンロードしたNEUTRINOフォルダの\score\musicxml内に入れます。
名前は英文字+数字でつけてください
合成
NEUTRINOフォルダ内のRun.batまたはRun.shを編集します。
set BASENAME=のところをにさっきつけた名前を入れます。
音声モデルをデフォルト以外のにしたい人はset ModelDirをそのモデルのフォルダ名にしましょう。
そしてこれを保存しRun.batまたはRun.shをクリックしましょう、実行されるはずです。そしてoutputフォルダに完成品があるはずなので見ましょう。

_nsfファイルのほうが好きです(2つは合成方式が違います。聞き比べてみるのもよいです)
声が高すぎる低すぎるときはMusescoreでオク上げ下げをしてください。Ctrl+AをしてからCtrl+↑または↓です
(余談ですがRun.batの中の-mオプションを取り除けばCUDAなしで使えるんでしょうか?)
今回はきりたんに歌ってもらいました。
合成した音声をso-vits-svcフォルダのrawファイルに入れましょう。
so-vits-svcで合成
サンプルの用意
本人の声以外聞こえないようなサンプルが必要です
僕はアニメ本編を10分ごとに分割し、ボーカル分離サービスにひたすら流し込み、それをフレーズごとに分割しサンプルとしました。2秒から15秒がいいらしいです。
100個程度だとノイズの大きなモデルになってしまいます。少なくとも300個、できれば500個くらいを目標にかき集めましょう
集めたサンプルをso-vits-svcフォルダーのdataset_rawにその人用のフォルダーを作って入れます。
学習
入れたらPower shellをso-vits-svcフォルダで起動し
python resample.py
python preprocess_flist_config.py
python preprocess_hubert_f0.py
python train.py -c configs/config.json -m 44k
馬鹿みたいに時間がかかります
python train.py -c configs/config.json -m 44k | grep "44k:====>"ubuntuの人はgrepをつけると進捗が見やすくてよいです。
じぶんはG_100000が生成されたところで終わりにしています。どのくらいで終わらせるべきなのかはモデルによって違うので、音声合成して確かめながら判断です。
音声合成
python inference_main.py -m "logs/44k/G_一番大きいやつ" -c "configs/config.json" -n "元データ.wav" -t 0 -s "スピーカフォルダ名"これで合成されるはずです
詳しくは公式のREADME.mdを読みましょう
生成物
ひなた
みやこ
どちらもプニプニがクニクニになっていますが、とても似ています。
とくにみやこはノイズが少なく合成音声特有の不自然さもないです。
ひなたのサンプル数は300個でみやこは500個です。
きれいに歌わせるには500個以上必要だと思います
合成元(私に天使が舞い降りた!)
第一話は無料なので見ましょう!

終わり
何かエラーが出たら書き込んでください
